신경망
softmax
선형모델의 경우 Y = XW + B와 같이 표현된다. 이에 softmax를 이용해서 우리는 분류 문제를 해결한다.
즉 softmax를 통해 선형모델을 마치 우리가 원하는 의도로 바꿀 수 있다.

활성함수
softmax 같이 우리는 활성화 함수를 사용하면 데이터를 비선형 함수를 바꿔줄 수 있다.
softmax는 출력물의 모든 값을 다 고려해서 계산하지만 활성함수는 해당 주소의 출력값만으로 계산이된다. 실수가 들어오고 실수가 나온다.
선형모델로 나온 출력물을 비선형 모델로 변형 시킬수 있다. 이렇게 변한 벡터를 hidden vector 라고 부른다.
활성함수를 쓰지 않고 딥러닝을 구현하면 선형모형과 차이가 없다. << 이부분이 뭔말인고하여 찾아보았다.
<활성함수를 써야되는 이유> (참고: https://han-py.tistory.com/211)
우선 활성함수를 써야된다고 여러 이유를 들며 설명을 했는데 하나도 와닿지가 않는다. 선형모형과 왜 차이가 있어야되는지, 왜 굳이 비선형 함수로 만들어야 좋은지 등등.. 이에 대해 설명하겠다.
선형 시스템은 아무리 복잡하게 만들고 싶어도 망이 깊어지지 않는다. 즉 hidden layer가 하나밖에 안나온다. 뭔말인가?
선형 모델은 f(ax+by) = af(x) + bf(y)가 성립한다. 이거랑 망이 안깊어지는게 무슨 상관인가?
신경망의 구조는 아래와 같이 Input layer(Data) / Hidden layers / Output layer로 돼있다.
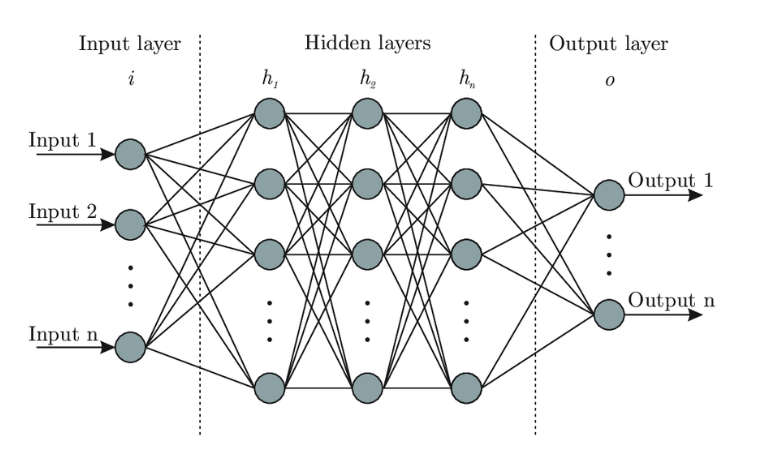
선형 모델은 f(ax+by) = af(x) + bf(y) 가 성립하기 때문에 Hidden layer를 1개 이상 더 깊게 만들 수가 없다는거다.
하지만 활성함수를 사용하면 출력값이 선형으로 나오지 않기 때문에 망을 깊게 만들 수 있다. 그래서 relu같은 활성함수를 hidden layer에 계속 넣어주는건가보다. (선형으로 변한 data를 다시 비선형으로 만들고 layer를 진행하고 다시 선형이 된 data를 비선형으로 바꿔주고... >> 아래그림 참고 δ(z)가 활성함수)
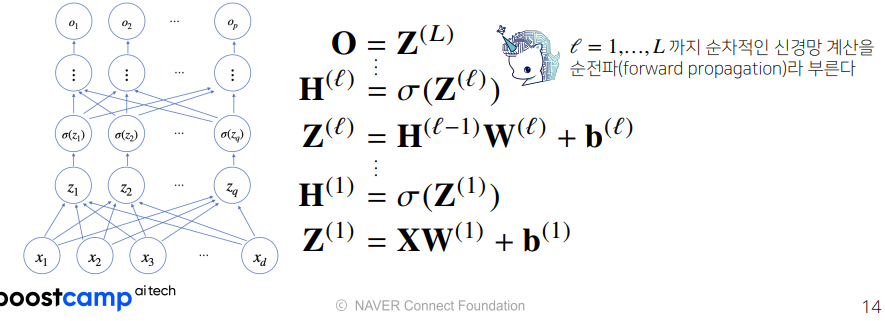
hidden layers가 많으면 / 신경망이 깊으면 뭐가 좋은가??
딥러닝은 말그대로 deep하게 배우는 모델이다. 즉 hidden layers를 늘리면서, 신경망을 깊게함으로 인해 장점을 얻는 학습법이다. 그치만 왜 인가..?
1. 망이 깊어지면(hidden layers가 많아지면) 매게 변수가 많이 필요 없다. layer가 깊어지면 같은 수준의 정확도의 layer를 구현하더라도 매개변수가 적게 필요하다. == 목적함수를 근사하는데 필요한 뉴런(노드)의 숫자가 훨씬 빨리 줄어들어 더 효율적으로 학습이 가능하다
2. 필요한 연산의 수가 줄어든다. Fiter의 크기를 줄이고, 망을 깊게 만들면 연산 횟수가 줄어들면서 정확도를 유지하는 결과를 낸다.
역전파 알고리즘
미분 연쇄 법칙
미분을 개념이 가물가물해서 다시 짚고 간다.
- 변화량 (delta, δ) : dx는 어떤 구간에서의 x의 변화량이다. 따라서 dy/dx는 x변화량에 따른 y의 변화량 즉, 기울기다.
dz/dx를 구하고 싶다면 아래 그림처럼 dz/dw * dw/dx 를 통해 dz/dx 를 구할 수 있다.

역전파 알고리즘은 미분 연쇄 법칙을 이용한다. dO/dX를 구하고 싶다면 O=Z(L)부터 Z(1) = XW(1)+b(1)까지의 미분값을 모두 곱해주면 된다.
dO / dZ(L) = ~~~
dZ(L) / dH(L-1) = ~~~~
dH(L-1) / dZ(L-1) = ~~~
dZ(L-1) / dH(L-2) = ~~~~
.....
dH(1) / dZ(1) = ~~~
dZ(1) / dX = ~~~~
이를 다 곱하면 dO/dX를 구할 수 있다.

실제 딥러닝에서 backpropagation(역전파)를 사용하려면 층마다 미분 값들을 메모리에 저장해놔야된다. 따라서 fowardpropagation 보다 메모리를 많이 먹는다.
예제: 2층 신경망
각 벡터별 편미분 >> 잘 이해 안감...

'기타 > 리뷰 및 경험담 - p stage' 카테고리의 다른 글
| [AI Math] 경사하강법 (0) | 2021.09.22 |
|---|---|
| [AI Math] 벡터와 행렬 (0) | 2021.09.22 |
| [부스트캠프] (1주차) 필수 과제 1~5 관련 정리 (0) | 2021.08.06 |

